Constrained Space, Better Code: MXCP & Claude Skills

Introduction
Large Language Models have become remarkably effective at software development tasks, from navigating large codebases and refactoring complex logic to identifying bugs and generating working implementations with impressive speed. At the same time, they can just as easily break a functioning system, introduce subtle errors, or produce code that looks correct but fails in practice, a behavior that follows directly from how LLMs generate code in a largely unconstrained space. When there is no built-in validation, the gap between productive automation and failure becomes thin, making reliability the central challenge in real-world systems.
In this post, we explore how Claude Code, when augmented with Skills and operating inside the MXCP framework, addresses this challenge by deliberately restricting the coding space and reinforcing correctness through structure and feedback. Skills provide concrete, in-context knowledge about how MXCP is intended to be used, while the framework constrains generation to a small set of well-defined, valid operations and enforces schemas, constraints, and operational guarantees. In real-world projects, this combination has enabled Claude Code to generate even complex MXCP-based MCP servers with minimal guidance, reducing development timelines from weeks to days while increasing confidence in correctness and stability, and providing a predictable path toward production-ready systems.
A Core Problem: Unconstrained Generation
At their core, LLMs are probabilistic token generators. Given a prompt, they predict the next token based on learned patterns, not on an understanding of correctness or system constraints. The space of possible tokens they can produce is effectively infinite, while the subset that represents valid, safe, and useful code within a real system is relatively small. When this output space is left unconstrained, even highly capable models are forced to guess what “valid” looks like. Small variations in context or probability can then push the model toward drastically different outcomes - some correct, others destructive. The fundamental problem is not model intelligence, but the absence of boundaries that define what is allowed to exist.
Why Validation Changes Model Behavior

Validation introduces feedback, something raw LLM generation fundamentally lacks. Without validation, a model can only optimize for plausibility - producing code that looks correct but may fail at compile time, runtime, or under real workloads. When validation mechanisms such as tests, schemas, type checks, or runtime assertions are built into the system, they provide an explicit signal of success or failure. This signal allows the model to iteratively adjust its output, converging toward correctness rather than guessing it in a single attempt. Validation does not make the model smarter; it makes the environment smarter, transforming one-shot generation into an adaptive process grounded in observable outcomes.
Structural Constraints, Not Better Prompts
A software framework is a reusable, semi-complete application that provides a predefined structure for developing software by defining control flow, extension points, and common functionality.
Frameworks are the mechanism through which constraints and validation become enforceable. Instead of relying on prompts to describe what a model should or should not do, frameworks encode these rules directly into the system. They restrict the model’s output space by exposing only valid operations, enforcing schemas and types, and embedding domain rules into the execution flow.
In such systems, invalid states are impossible to express. By shaping the environment in which generation occurs, frameworks turn probabilistic models into reliable components, ensuring that creativity exists only within well-defined boundaries.
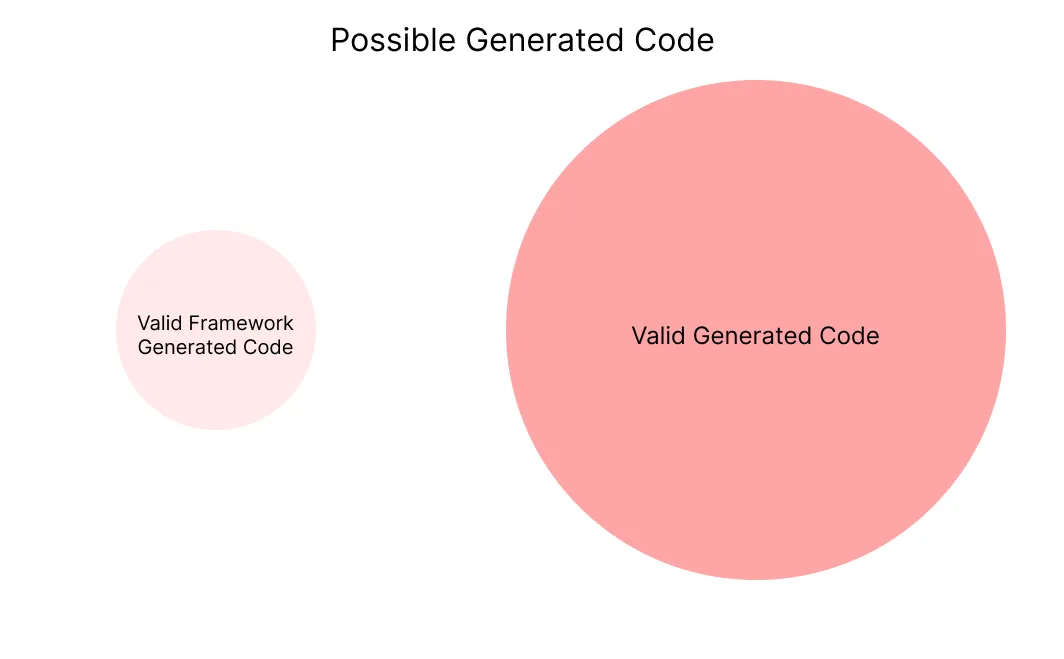
Familiarity Matters: When Models Know the Framework
Frameworks only provide their full benefits when the model understands how to use them. If a framework is widely adopted and well represented in training data, LLMs tend to perform extremely well. A common example is frontend development: code generated with React is often significantly higher quality than equivalent implementations written in vanilla HTML and JavaScript. The model has seen enough real-world React code to internalize its patterns, conventions, and best practices.
The situation changes dramatically when the framework is custom or poorly represented in training data. In those cases, the model has no reliable prior knowledge to draw from and is forced to rely on guesswork. Sometimes this guesswork succeeds, but just as often it produces incorrect, inconsistent, or entirely unusable output. Without additional structure, the benefits of a framework alone are not enough.
Claude Skills to the Rescue
Claude Skills, developed by Anthropic, provide a powerful solution to this problem. Skills allow developers to preload useful information, scripts, references, and assets that support in-context learning when working with a framework. Instead of relying on vague natural language descriptions, the model gains access to concrete, executable knowledge about how the framework should be used.
By embedding this information directly into the model’s working context, Skills effectively “train” the agent at runtime. This dramatically reduces guesswork and aligns the model’s behavior with the framework’s intended design. When combined with a constrained and validated environment, Skills enable LLMs to work reliably even with custom or domain-specific frameworks.
Generating an MCP Server: A Concrete Example
The Model Context Protocol (MCP) is a widely used protocol designed to enable communication between agents and systems. While there are multiple MCP implementations across different programming languages, they all share a common characteristic: the developer is free to implement almost anything. This flexibility is powerful, but it comes at a cost.
Building a reliable MCP server requires far more than just implementing protocol handlers. Production-grade systems need observability, logging, validation, testing, authentication, and policy enforcement. Implementing these concerns repeatedly results in large amounts of boilerplate code. This boilerplate significantly increases the number of tokens that must be included in the model’s context for effective code generation, which directly increases cost. It also creates long-term maintenance problems: copying and adapting similar MCP servers across projects leads to divergence, fragility, and codebases that are difficult for both humans and LLMs to reason about.
This is a textbook case for introducing a framework.
MXCP: A Production-Ready MCP Framework
Most LLM-driven agent workloads follow a small number of recurring patterns: CRUD operations over data and the execution of custom business logic. MXCP is built around this observation and deliberately restricts the execution space to three well-defined domains: YAML for endpoint definitions, SQL for data access (over any supported data source), and Python for custom logic.
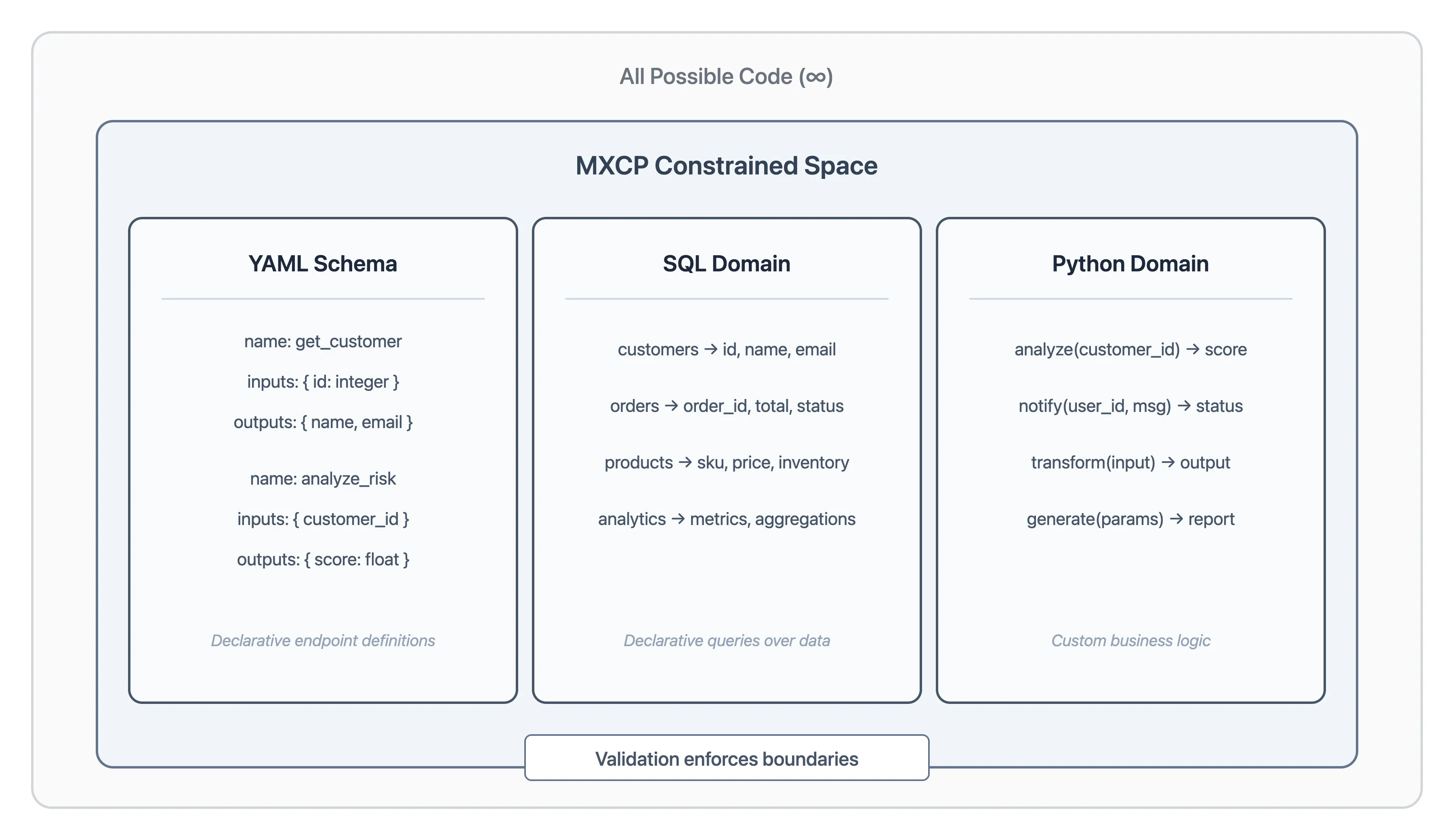
With MXCP, developers define MCP endpoints declaratively using a YAML schema that specifies inputs and outputs. The executable behavior of each endpoint is then implemented using either SQL or Python - YAML handles the “what,” while SQL and Python handle the “how.” This design dramatically narrows the space of possible implementations. While the space remains theoretically infinite, it is constrained to forms that are predictable, auditable, and easier for models to generate correctly.
MXCP also provides built-in support for observability, logging, drift detection, policy enforcement, and authentication. Because these concerns are handled by the framework, the coding agent does not need to generate, read, or maintain large volumes of boilerplate code. This reduces context size, lowers token costs, and improves generation quality.
Validation as a Feedback Loop
Restricting the implementation space is necessary, but it is not sufficient. Even within a constrained framework, the space of possible implementations remains infinite - just a much smaller and more structured infinity than unconstrained code generation. Models can still make incorrect assumptions, misunderstand requirements, or choose suboptimal implementations within those bounds.
This is where validation becomes essential. MXCP provides multiple layers of validation and testing that create explicit feedback loops for the coding agent:
mxcp validate- schema validation and type checkingmxcp test- end-to-end unit tests for MCP endpointsmxcp lint- quality and consistency checks for MCP implementationsmxcp evals- evaluation of how well different models understand and interact with the MCP server- Custom unit tests - project-specific validation logic
Each layer further narrows the effective space the model can operate in. While the theoretical space of valid implementations remains infinite, repeated validation collapses it toward a subset that is correct, maintainable, and production-ready. The coding agent is no longer exploring an open-ended search space, but iterating within a guided process where failures are observable and correctness is reinforced. Reliability, in this setup, is not assumed - it is converged upon.
Real World
In real-world projects, Claude Code paired with the mxcp-expert skill has been able to generate even highly complex MXCP servers with minimal guidance. Tasks that previously required weeks of development were reduced to a single day at most, while confidence in correctness and stability increased significantly. We are now on track to automate the entire MCP server development process. This improvement did not come from better prompts, but from operating within a constrained and validated framework.
flowchart TB
User["👤 User"]
Agent["🤖 Coding Agent"]
MXCP["⚙️ MXCP Framework"]
User -->|"Intent & requirements"| Agent
Agent -->|"Results & feedback"| User
Agent -.->|"Guards against errors"| User
Agent <-->|"Validate & test"| MXCP
MXCP -->|"Constraints & guarantees"| Agent
The relationship between the user, the coding agent, and the MXCP framework is inherently multidirectional. The user defines intent and reviews outcomes, the coding agent generates implementations and iteratively validates and tests them through MXCP, and the framework itself enforces structural and safety guarantees. In this setup, the agent not only produces code but also actively prevents critical failures - for example, by avoiding secret exposure, a class of errors Claude Code is explicitly designed to guard against.
Evaluation
We have observed these patterns consistently across multiple production projects. To make the difference concrete, we ran a controlled comparison: two identical Claude Code sessions were given the same task. One session used the MXCP framework with the mxcp-expert skill, and the other used the pure MCP Python SDK with mcp-creator skill. The goal was not to prove that one approach is more capable, but to show how constraints and built-in validation affect reliability, iteration count, and implementation complexity.
The task: Build a production-ready e-commerce MCP server with 9 tools: CRUD operations (create_product, get_product, update_product, delete_product, list_products), analytics (get_sales_summary, get_category_stats, get_low_stock_report, get_top_sellers), and role-based authentication (admin-only vs public access). The server must use parameterized queries, validate all inputs, implement soft deletes, and pass all validation checks. The database includes 20+ products across 4 categories and 50+ sales records.
MXCP vs Pure MCP: Side-by-Side Comparison
MXCP produced 65% less code (843 vs 2,404 lines), used 70% fewer output tokens (~15K vs ~50K), and completed 50% faster (5 min vs 10 min). Both implementations delivered all 9 tools with identical functionality: parameterized queries, input validation, role-based authentication, and proper error handling. The pure MCP version required 3x more test cases (56 vs 18) to achieve similar coverage - a direct consequence of having to test manually what MXCP validates by design. The difference is how reliably the framework guides generation toward a clean, production-ready result.
Follow-up: Extending the Implementation
Initial implementation is only part of the story. Real-world systems evolve as requirements grow. To simulate this, we ran a follow-up experiment: a user returns one month later to extend the existing implementation with features typically required for production - additional policies, a complementary CSV data source for cross-queries, auditing, observability, and LLM evals.
The extension task: “Consume a complementary CSV data source for cross-queries, add relevant policies, enable auditing and observability, and include LLM evals.”
Extension Effort: Adding Features Later
Cost of extending an existing implementation with new requirements
* MCP agent exhausted 200K context window (~100K output tokens) during extension
The MXCP extension was straightforward: policies are declarative CEL rules, CSV data sources are configured in YAML, auditing and observability are single-line configuration toggles, and LLM evals are defined alongside tool definitions. Features that required additional code in MXCP are features the framework was designed to support - the agent simply activated them.
The pure MCP extension tells a different story. Adding the same features required implementing policies from scratch (669 lines), building an observability module (650 lines), creating an auditing system (560 lines), and developing CSV tools (478 lines) - each with comprehensive tests. The agent consumed ~110K tokens and exhausted the context window, requiring careful management to complete. What MXCP enables with configuration, pure MCP requires as custom infrastructure.
Development Process Comparison
How Claude Code approached the same task with different tools
- 1
mxcp initScaffold project structure - 2
Write YAML + Python + SQL9 tool schemas + 2 impl files - 3
CEL policy rulesDeclarative auth (admin-only) - 4
mxcp validate + test + lintAll 18 tests pass - 5
mxcp serveStart server
- 1
mkdir + venv + pipCreate project structure manually - 2
Write 6 Python filesServer, models, DB, auth, tests - 3
Manual auth middlewareAPI key param per tool - 4
pytest + ruff + mypy56 tests, multiple lint passes - 5
python -m serverStart server
The workflow difference matters. MXCP provides a single path: mxcp init, write YAML and Python, then mxcp validate, mxcp test, mxcp lint - all integrated, all immediate. Pure MCP requires assembling project structure, tests, and quality checks manually using pytest, ruff, and mypy. The MXCP implementation is declarative - endpoints in YAML, validation in schemas, tests alongside definitions. The pure MCP version concentrates more logic in custom Python, which works but requires more coordination to get right. The framework does not remove work - it standardizes it, making successful outcomes easier to reproduce.
During the pure MCP implementation, the agent encountered database concurrency issues that required additional debugging and iteration to resolve - a common problem when building data-driven services from scratch. MXCP handles connection pooling and concurrent access by default, eliminating this entire class of issues before they occur.
Both approaches passed their validation suites. The framework trades some flexibility for guardrails, and in LLM-driven development those guardrails translate directly into more consistent results. But the difference extends beyond correctness - MXCP includes production concerns that pure MCP leaves as future work:
What You Get Out of the Box
Production-ready features included vs. features you'll need to build
| Feature | MXCP | Pure MCP |
|---|---|---|
| Schema validation | ✓ | ✗ |
| Input type checking | ✓ | ✗ |
| Test runner | ✓ | ✗ |
| Observability & logging | ✓ | ✗ |
| Auditing | ✓ | ✗ |
| Multi-source data | ✓ | ✗ |
| Health checks | ✓ | ✗ |
| Configuration management | ✓ | ✗ |
| Connection pooling | ✓ | ✗ |
| Authentication | ✓ | ✗ |
| Policy enforcement | ✓ | ✗ |
| Drift detection | ✓ | ✗ |
| Tool extensibility | ✓ | ✗ |
| LLM evals | ✓ | ✗ |
These gaps are manageable in a small project, but they compound as systems grow. The pure MCP implementation shows patterns that degrade with complexity: tight coupling, validation logic that can drift from schemas, and no hooks for cross-cutting concerns. MXCP addresses these at the framework level - observability, authentication, and policy enforcement are part of the execution model, not afterthoughts. When an LLM generates within MXCP, it inherits those guarantees automatically. The framework does not just constrain what can be generated - it makes the default output closer to production-ready.
Conclusion
LLMs can act as autonomous authors of software, but reliability emerges from the systems they operate within. Their probabilistic nature is not a weakness to be eliminated, but a property to be shaped through structure and feedback. By restricting the space of valid outputs and introducing validation as a continuous signal, frameworks like MXCP turn autonomous generation into predictable execution. As the evaluation shows, these constraints reduce iteration, cognitive load, and failure modes while improving production readiness. In practice, reliability at scale comes from environments that encode boundaries, guarantees, and verification, not from prompts alone.